MapReduce Online
Table of Contents
http://db.cs.berkeley.edu/papers/nsdi10-hop.pdf
1 Abstract
- In this pa- per, we propose a modified MapReduce architecture that allows data to be pipelined between operators. This ex- tends the MapReduce programming model beyond batch processing, and can reduce completion times and im- prove system utilization for batch jobs as well.
- We present a modified version of the Hadoop MapReduce framework that supports online aggregation , which al- lows users to see “early returns” from a job as it is being computed.
- Our Hadoop Online Prototype (HOP) also supports continuous queries, which enable MapReduce programs to be written for applications such as event monitoring and stream processing.
- HOP retains the fault tolerance properties of Hadoop, and can run unmodified user-defined MapReduce programs. 不需要修改MapReduce代码完全在framework层面上完成。
#note: 文章后面会讲到这三个特性分别是用来做什么的,以及如何做到的
2 Introduction
Pipelining provides several important advantages to a MapReduce framework, but also raises new design chal- lenges. We highlight the potential advantages first:
- A downstream dataflow element can begin consum- ing data before a producer element has finished ex- ecution, which can increase opportunities for par- allelism, improve utilization, and reduce response time. (pipeline可以增加并行度,提高利用率以及减少响应时间)
- Since reducers begin processing data as soon as it is produced by mappers, they can generate and re- fine an approximation of their final answer during the course of execution. This technique, known as online aggregation, can reduce the turnaround time for data analysis by several orders of magni- tude. (所谓的online aggregation就是指能够根据部分数据做一个总体结果的估计,很明显这个是依赖于pipeline的)
- MapReduce jobs that run continuously, ac- cepting new data as it arrives and analyzing it im- mediately. This allows MapReduce to be applied to domains such as system monitoring and stream processing. (这种所谓的continuous query就是指task是连续运行的,可以用来一些实时的处理和统计,和明显这个是依赖于pipeline的)
Pipelining raises several design challenges.
- First, Google’s attractively simple MapReduce fault tolerance mechanism is predicated on the materialization of inter- mediate state. In Section 3.3, we show that this can coex- ist with pipelining, by allowing producers to periodically ship data to consumers in parallel with their materializa- tion. (MapReduce模型中的materialization是为了做fault-tolerant,但是如果使用pipelining的话如何来做这件事情)
- A second challenge arises from the greedy com- munication implicit in pipelines, which is at odds with batch-oriented optimizations supported by “combiners”: map-side code that reduces network utilization by per- forming compression and pre-aggregation before com- munication. (如何在pipeline上面减少通信,因为batch通信可以通过combiner来完成)
- Finally, pipelining requires that producers and consumers are co-scheduled intelligently(这个和pipline实现相关,pipeline可能需要做好producer和consumer的协调)
3 Background
3.1 Programming Model
3.2 Hadoop Architecture
3.3 Map Task Execution
3.4 Reduce Task Execution
4 Pipelined MapReduce
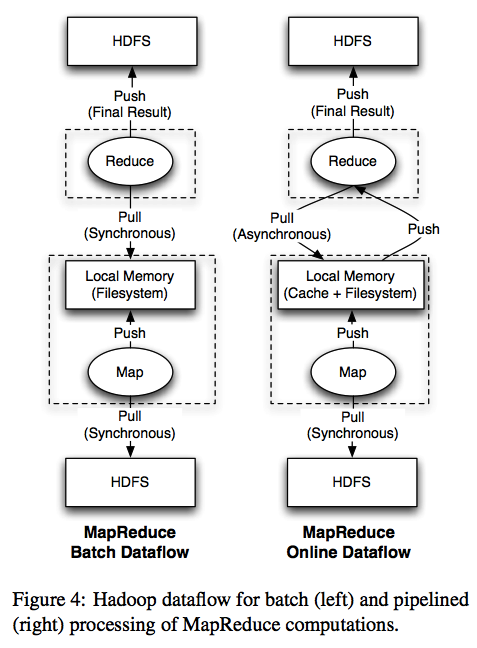
4.1 Pipelining Within A Job
To sup- port pipelining, we modified the map task to instead push data to reducers as it is produced.
4.1.1 Naive Pipelining
- For purposes of discus- sion, let us assume that there are enough free slots to as- sign all the tasks for each job. 这个假设非常重要,就是假设有足够的槽位每个task都能够正常启动
- We modified Hadoop so that each reduce task con- tacts every map task upon initiation of the job, and opens a socket which will be used to pipeline the output of the map function.
- As each map output record is produced, the mapper determines which partition (reduce task) the record should be sent to, and immediately sends it via the appropriate socket. (mapper产生输出立刻就进行发送,注意这个地方没有做排序什么工作,所以对reduce压力可能回比较大)
- A reduce task accepts the pipelined data it receives from each map task and stores it an in-memory buffer, spilling sorted runs of the buffer to disk as needed.(reducer接收之后进行排序必要的话spill到磁盘上面)
- Once the reduce task learns that every map task has completed, it performs a final merge of all its sorted runs and applies the user-defined reduce function as normal, writing the output to HDFS.
4.1.2 Refinements
While the algorithm described above is straightforward, it suffers from several practical problems.
- First, it is possible that there will not be enough slots available to schedule every task in a new job.
- if a reduce task has not yet been scheduled, any map tasks that produce records for that partition simply write them to disk. Once the reduce task is assigned a slot, it can then fetch the records from the map task, as in stock Hadoop.(如果reducer没有调度上的话,那么mapper将这个输出直接写盘,然后等待reducer调度之后按照原来的方式获取)
- Opening a socket be- tween every map and reduce task also requires a large number of TCP connections.
- To reduce the num- ber of concurrent TCP connections, each reducer can be configured to pipeline data from a bounded number of mappers at once; the reducer will pull data from the re- maining map tasks in the traditional Hadoop manner.(对于大量连接数目的解决办法也是一样的,限定使用pipelining的mapper数量)
- the user-defined map function was invoked by the same thread that wrote output records to the pipeline sockets. This meant that if a network I/O blocked (e.g. because the reducer was over-utilized), the mapper was prevented from doing useful work.
- We solved this problem by running the map function in a separate thread that stores its output in an in-memory buffer, and then having another thread pe- riodically send the contents of the buffer to the pipelining reducers.(这个问题的解决就是将输出数据存放在一个in-memory buffer里面,单独开辟发送线程将buffer data异步地发送出去)
4.1.3 Granularity of Map Output
- Another problem with the naive design is that it eagerly sends each record as soon as it is produced, which pre- vents the use of map-side combiners. By eagerly pipelining each record as it is produced, there is no op- portunity for the map task to apply a combiner function.(map side不能够执行combiner)
- A related problem is that eager pipelining moves some of the sorting work from the mapper to the reducer. (reducer现在需要完全地进行sort和group)
- We addressed these issues by modifying the in- memory buffer
- In- stead of sending the buffer contents to reducers directly, we instead wait for the buffer to grow to a threshold size. (in-memory buffer本地会先缓存然后发送)
- The mapper then applies the combiner function, sorts the output by partition and reduce key, and writes the buffer to disk (mapper首先对in-memory buffer做排序以及combine,然后spill到disk上面)
- A second thread monitors the spill files, and sends them to the pipelined reducers.(另外发送线程直接发送spill file,或者是reduce没有启动的话,那么reducer直接获取spill file)
- If the reducers are able to keep up with the map task and the network is not a bottleneck, a spill file will be sent to a reducer very quickly after it has been produced
- However, if the reducer begins to trail the mapper, the number of unsent spill files will grow. In this case, the mapper periodically applies the com- biner function to the spill files, merging multiple spill files together into a single larger file. (如果spill file积累很多的话,那么可以对这些spill file做merge以及combine)
- This has the effect of adaptively moving load from the reducer to the map- per or vice versa, depending on which node is the current bottleneck. (这样可以动态地调整mapper和reducer之间的负载比例)
4.2 Pipelining Between Jobs
Unfortunately, the computation of the reduce function from the previous job and the map function of the next job cannot be overlapped: the fi- nal result of the reduce step cannot be produced until all map tasks have completed, which prevents effective pipelining.
4.3 Fault Tolerance
- To recover from map task failures, we added some bookkeeping to the reduce task to record which map task produced each pipelined spill file.
- To simplify fault tolerance, the re- ducer treats the output of a pipelined map task as “ten- tative” until the JobTracker informs the reducer that the map task has committed successfully. 在mapper完全完成之前,reducer认为这些文件全部都是tentative的,相当于全部都是临时性的。
- The reducer can merge together spill files generated by the same uncom- mitted mapper, but won’t combine those spill files with the output of other map tasks until it has been notified that the map task has committed. 但是对于tentative的spill files不会和那些已经运行完成的mapper输出的spill file混在一起。
- If a reduce task fails and a new copy of the task is started, the new reduce instance must be sent all the in- put data that was sent to the failed reduce attempt.
- Our technique for recovering from map task failure is straightforward, but places a minor limit on the reducer’s ability to merge spill files. To avoid this, we envision in- troducing a “checkpoint” concept: as a map task runs, it will periodically notify the JobTracker that it has reached offset x in its input split. 为了更快地进行failover,mapper进行bookkeep做checkpoint, 下次运行从某个offset开始运行并且只是发送增量的数据。
4.4 Task Scheduling
4.5 Performance Evaluation
5 Online Aggregation
Traditional MapReduce implementations provide a poor interface for interactive data analysis, because they do not emit any output until the job has been executed to completion. However, in many cases, an interactive user would prefer a “quick and dirty” approximation over a correct answer that takes much longer to compute.
We show that online aggregation has a minimal impact on job completion times, and can often yield an accu- rate approximate answer long before the job has finished executing.
5.1 Single-Job Online Aggregation
- We can support online aggregation by sim- ply applying the reduce function to the data that a reduce task has received so far. We call the output of such an intermediate reduce operation a snapshot.(主要就是针对pipelining过程中reducer接收到的部分数据做一个snapshot, 然后根据部分数据计算结果。而实际上计算这个snapshot结果很大程度上和计算全量数据存在关联)
- Users would like to know how accurate a snapshot is: that is, how closely a snapshot resembles the final out- put of the job. Hence, we report job progress, not ac- curacy: we leave it to the user (or their MapReduce code) to correlate progress to a formal notion of accuracy. We give a simple progress metric below. (通过job progress来估算snapshot对于全量数据的准确性,而framework是没有办法预知的)
- Snapshots are computed periodically, as new data ar- rives at each reducer. The user specifies how often snap- shots should be computed, using the progress metric as the unit of measure. The user may also specify whether to include data from tentative (unfinished) map tasks.(用户自己来决定到progress都什么地方可以做一次online aggregation,并且可以选择tentative mapper输出)
- Note that if there are not enough free slots to allow all the reduce tasks in a job to be scheduled, snapshots will not be available for reduce tasks that are still waiting to be executed. The user can detect this situation (e.g. by checking for the expected number of files in the HDFS snapshot directory), so there is no risk of incorrect data, but the usefulness of online aggregation will be compro- mised. (这是一个非常实际的情况,就是说如果progress已经到了25%,但是实际上只有部分reduce执行完成,部分reducer因为slot原因没有调度上,也就是说整个snapshot结果是具有偏袒性的,不能够作为全量数据的approximation。这样的话结果虽然是正确的,但是snapshot意义就不是很大)。
5.1.1 Progress Metric
- As each map task executes, it is assigned a progress score in the range [0,1], based on how much of its input the map task has consumed. (每个mapper根据input/output计算一个progress score)
- if a reducer is connected to 1/n of the total number of map tasks in the job, we divide the average progress score by n. (每个reducer如果只是链接上了1/n部分的mapper的话,那么progress scroe需要除以n)
5.1.2 Evaluation
5.2 Multi-Job Online Aggregation
5.2.1 Evaluation
6 Continuous Queries
Our pipelined version of Hadoop allows an alternative architecture: MapReduce jobs that run continuously, ac- cepting new data as it becomes available and analyzing it immediately. This allows for near-real-time analysis of data streams, and thus allows the MapReduce program- ming model to be applied to domains such as environ- ment monitoring and real-time fraud detection.
6.1 Continuous MapReduce Jobs
- A bare-bones implementation of continuous MapReduce jobs is easy to implement using pipelining. No changes are needed to implement continuous map tasks: map out- put is already delivered to the appropriate reduce task shortly after it is generated. (一旦实现pipelining的话,那么实现continuous query就非常简单)
- We added an optional “flush” API that allows map functions to force their current out- put to reduce tasks. When a reduce task is unable to ac- cept such data, the mapper framework stores it locally and sends it at a later time. (添加flush API允许mapper将之前的输出传递到reducer部分,但是如果reduce不能够接收的话,那么这个数据会被缓存起来,相当于这个flush API是一个辅助性质的API)
- To support continuous reduce tasks, the user-defined reduce function must be periodically invoked on the map output available at that reducer. Applications will have different requirements for how frequently the re- duce function should be invoked: possible choices in- clude periods based on (framework定期调用reduce函数来进行处理,对于这个周期可以使用下面三个指标进行指定):
- wall-clock time,
- logical time (e.g. the value of a field in the map task output),
- and the num- ber of input rows delivered to the reducer.
6.2 Fault Tolerance
#note: 这里只需要考虑reduce挂掉的情况。注意方式1重跑是会带有副作用的,而方式2重跑是没有副作用的
- However, many continu- ous reduce functions (e.g., 30-second moving average) only depend on a suffix of the history of the map stream. This common case can be supported easily, by extending the JobTracker interface to capture a rolling notion of re- ducer consumption. Map-side spill files are maintained in a ring buffer with unique IDs for spill files over time. When a reducer commits an output to HDFS, it informs the JobTracker about the run of map output records it no longer needs, identifying the run by spill file IDs and offsets within those files. The JobTracker then can tell mappers to delete the appropriate data. (对于reducer只需要过去少量时间输入就可以恢复的,那么mapper spill file可以存储为ring buffer格式,定期删除一些已经没有用的)
- In principle, complex reducers may depend on very long (or infinite) histories of map records to accurately reconstruct their internal state. In that case, deleting spill files from the map-side ring buffer will result in poten- tially inaccurate recovery after faults. Such scenarios can be handled by having reducers checkpoint internal state to HDFS, along with markers for the mapper off- sets at which the internal state was checkpointed. The MapReduce framework can be extended with APIs to help with state serialization and offset management, but it still presents a programming burden on the user to cor- rectly identify the sensitive internal state.(对于reducer需要过去很长时间输入才能够恢复的,那么就需要考虑通过做checkpoint保存状态来回滚)